Across many business use cases and verticals, researchers and engineers are constantly discussing the value of AI (Artificial Intelligence) that can bring infinite opportunities. However, we overlook the steps that should be taken to apply AI-powered systems at scale. AI deployment can be exorbitant in terms of compute resources, time, and new wave of innovation that AI promises along with the proper training required for developers. A successful AI implementation needs to be done with tooling and processes in place around it.
A necessary condition for the process of deploying AI is having a proper understanding of your data. The performance of the AI model depends on the data tied to the data trained on. Another factor is selecting training data and how it is labelled. To navigate the complexities of AI at the enterprise level, companies are making use of an ecosystem approach to AI deployment that strengthens and seeks cooperation between multiple stakeholders. This ecosystem should be able to connect, building a more advanced and powerful system. In this ecosystem, technologies can connect whether it is mobile devices, automated cars, computers, or coffee machines.
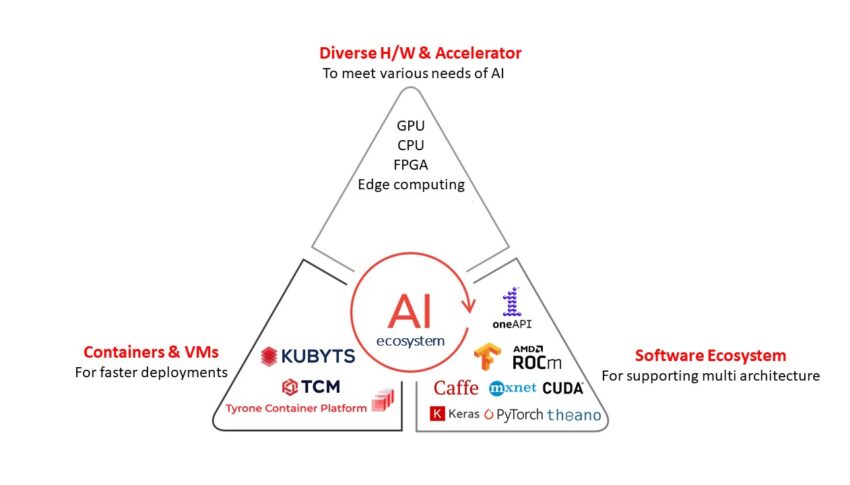
Need to Build AI Ecosystem
To serve big corporates, a platform providing innovative solutions is in huge demand. AI workloads are becoming critical in both data centre and edge devices such as cars, mobiles, and cameras. Classic machine learning techniques are specific to specific solutions such as statistical algorithms for decision trees, support vector, graph analytics, etc. A typical AI workflow consists of data that can be anything such as images, video, text, audio, etc. Using several frameworks like Caffe, PyTorch, TensorFlow, Keras, or OneAPI, data scientists or researchers will use it to build neural networks and then train that neural network with the data. The outcome of this will be a trained model that will be used in inference. Training a model is a complex task that requires a datacentre or a cloud where you can scale to thousands of servers to build the model. Inference runs in hybrid cloud where latency is not a problem.
With innovative CPU, GPU, FPGA hardware, CUDA-X libraries, and Container/VMs, your company requires the right infrastructure to scale from experimentation to production. Each industry is going to have a different set of requirements and challenges. The key is to find where AI/ML solutions are most effective.
Three things are required to set your business for better productivity, they are Infrastructure such as CPU, GPU accelerated hardware, Containerization for faster deployments that are used to package the software, libraries and configurations, and software ecosystem that support multi-architecture to run multi-apps simultaneously.
Powering Innovation Through Extensive AI Ecosystem: Hardware Components
We provide everything you require to deliver new-generation products. The growing demand for high-performance hardware accelerators in chips is used to power the datacentres, employ AI technology in applications like object detection and recognition, deep learning, natural-language processing, and image classification. Therefore, hardware accelerator-based chips are increasingly overpowering traditional CPUs and GPUs due to their ability to perform faster processing of AI tasks with low power consumption.
Many companies like Intel and NVIDIA are offering a range of AI processors to AI software toolkits. So, AI designers are reviewing the availability of development tools for model creation, chip creation, and proof-of-concept designs with AI frameworks like PyTorch, Caffe, Tensorflow, etc. that are supported by the hardware accelerators. The Intel Xeon CPU with FPGAs defines standardized interfaces that FPGA developers and development and operations teams can use to hot-swap accelerators and enable application portability.
The ability of Containerisation for Faster Deployment
- AI/ML applications become more self-contained. They can be mixed and matched on any number of platforms with virtually no porting or testing required. Because of containerization, they can operate in a highly distributed environment and containers can accelerate the application deployment. The ability to expose the services of ML systems existing within the containers as microservices allows external applications, container-based or not, to leverage those services at any time, without having to move the code inside the application.
- The ability to cluster and schedule container processing that allows the ML application containers to scale.
- To access data using defined interfaces to handle complex data using abstraction layers. Containers have mechanisms built-in for external and distributed data access, so you can use common data-oriented interfaces to support multiple data models.
Build Optimised AI Software Solution, Stack
With a broad range of software tools, frameworks, and libraries that fulfil your data science needs from development to deployment and scaling, we support software frameworks that include:
- PyTorch (An open-source machine learning framework to facilitate research prototyping to production deployment.)
- Intel optimized TensorFlow (The core open-source library to develop and train the AI/ML model)
- Caffe (Open-source deep learning framework developed for Machine Learning)
- Apache’s MXNet (open-source deep learning software framework)
- Nvidia’s CUDA (A parallel computing platform and application programming interface (API) model)
- Keras (Industry-strength framework that can scale to a lot of clusters of GPUs)
- OneAPI (Intel’s OneAPI open-standard based programming model to simplify the development and deployment of data-centric workloads across CPUs, GPUs, and FPGAs.
- AMD ROCm (Open-source software development platform for HPC/Hyperscale-class GPU computing
- CUDA (NVIDIA’s parallel computing platform and application programming Interface)
Multi Architecture Platform to Address Developer Need
HPC and AI workloads demand diverse architectures, ranging from CPUs, general-purpose GPUs and FPGAs, to more specialized deep-learning NNPs, which Intel demonstrated earlier this monthsaid Raja Koduri, senior vice president, chief architect, and general manager of architecture, graphics, and software at Intel. Software platforms such as OneAPI helps developers to define programming for an AI-infused, multi-architecture world. To accomplish the need for diverse architectures such as CPUs, GPUs, and FPGAs, it is important to have data-centric workloads where multi-architectures are required. For each hardware platform, developers must maintain separate code bases that need to be programmed using separate libraries, languages, and software tools. So, the process is complex and time-consuming for developers.
TensorFlow, PyTorch, and MXNet is accelerated on single GPUs and can scale up to multiple GPU and multi-node configurations. CUDA, powered by Nvidia, enables developers to use the flexibility of GPU-optimised CUDA-X AI libraries to accelerate new frameworks and model architectures and speed up computing applications by utilizing the power of GPUs. CUDA toolkit provides everything you need to develop GPU-accelerated applications. The CUDA Toolkit has GPU-accelerated libraries, development tools, a compiler, and CUDA runtime. To solve the most profound challenges, scientists and researchers require a powerful tool at their fingertips.
Used widely in exascale supercomputers by Researchers and Scientists in the field of HPC and machine learning, AMD ROCm allows the flexibility for supporting multiple architectures if needed. A production-ready open software platform for HPC deployments consist of drivers, compilers, GPU monitoring tool, and libraries for relevant workloads. Integrated into many popular frameworks such as TensorFlow, PyTorch. With the latest industry standards, ROCm supports container deployment methods such as Docker, Kubernetes, and Slurm. ROCm’s open HIP code works on multiple GPUs and other hardware accelerators. Therefore, developers/ Data scientists can easily take workloads of multiple architectures allowing high performance and efficiency.
Why Kubyts?
Kubyts offers a group of GPU and CPU accelerated container applications and images for deep learning software, HPC applications, and HPC visualization tools. A complete package that can be easily deployed, ship, and run applications using container technology.
With the help of the variety of curated containers offered by Kubyts, developers can build cross-architecture applications using the power of Kubyts for different accelerators (CPUs, GPUs, FPGAs) that take advantage of its hardware features, faster deployment using VMs and containers, lower software development, deployment & maintenance costs. It reduces the effort to rewrite the applications across multi-architecture platform. As the applications and their dependencies are containerized into a single package therefore you can move them across multi-platform and hardware without any problem. Extremely good in delivering the agility and performance of DL/ML workloads that can be compared to bare-metal servers.
Why choose Kubyts for your Deep learning applications?
The unique hardware architecture, containerized application, and software platform that makes it a lot easier for developers and researchers to run multiple apps simultaneously.
- CPU, GPU, and FPGA accelerated unique solution that runs on containers and VMs.
- Repository of Containers with 100+ and 50+ containerized applications for DL, ML, and HPC workloads.
- Based on internet protocols such as DHCP and TFTP.
- Runs from anywhere on KUBYTS certified workstations and clusters.
- Increase your developer productivity with accelerated time for deploying and running applications in a few seconds.
- You can get instant access to our fully managed registry of optimized containers and choose your framework and compute resources as per your requirements.
- Ready to run containers that are fully CPU, GPU, and FPGA optimized.
- Developers and data scientists use KUBYTS as it lets you deploy AI frameworks and have an advantage with pre-trained models and model training scripts. So, they can focus on collecting better insights for building solutions to deliver business value.
- World-class industry-level support that enables you to get direct access to Tyrone AI experts with low risk, maximum system utilization, and user productivity.

